







Les différences clés entre Reverse ETL et iPaaS
4min • Édité le 12 mars 2025


Alexandra Augusti
Chief of Staff
Introduction
En moyenne, les entreprises utilisent jusqu’à 12 outils différents pour interagir avec leurs clients. Du site internet, en passant par les emails, les SMS ou les réseaux sociaux, les opportunités de toucher sa cible ne sont pas manquantes.
La multiplication des touches a permis une meilleure présence auprès des clients mais a aussi créé des silos de données. Les informations qui sont disponibles pour l’équipe CRM ne le sont pas nécessairement pour l’équipe média.
Pourtant, dans un environnement marketing où l’expérience omnicanale est essentielle, il est vital de désiloter la donnée et rendre l’information accessible à tous. La fluidité de l'information peut déterminer le succès d'une entreprise.
Désiloter la donnée signifie souvent créer et gérer des flux data réguliers entre tous les outils collectant et utilisant cette donnée. Malheureusement, cela demande des opérations data lourdes et gérer ses mouvements en interne n’est souvent pas rentable. Pour répondre à cet enjeu, différents outils ont été conçus pour autoriser le mouvement de données.
Cet article explore deux technologies principales dans ce domaine : le Reverse ETL (Extract, Transform, Load) et l'iPaaS (Integration Platform as a Service).
Qu'est-ce que le Reverse ETL ?
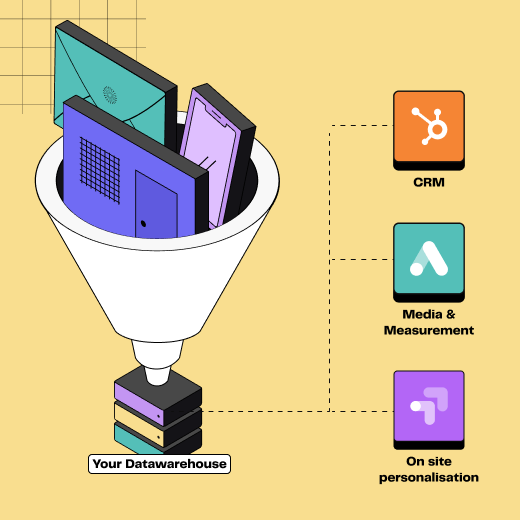
Le Reverse ETL est un processus qui consiste à extraire des données d'un data warehouse et à les charger dans des systèmes opérationnels (plateformes média, CRM, support, etc.). Cet outil est essentiellement utilisé pour dynamiser les opérations commerciales avec des données actualisées directement depuis la source de vérité centrale de l'entreprise.


Illustration du processus Reverse ETL
Le Reverse ETL joue un rôle primordial dans l'actualisation des systèmes opérationnels avec des données pertinentes pour des actions immédiates, facilitant une prise de décision rapide et informée au sein des entreprises.
Le Reverse ETL est souvent utilisé pour des cas d’usage marketing, pour mettre à jour les audiences utilisées dans les plateformes média, envoyer des conversions ou modifier des attributs dans le CRM. Le Reverse ETL peut cependant être utilisé par les équipes finance ou support.
Qu'est-ce que l'iPaaS?
L'iPaaS, ou Integration Platform as a Service, est une plateforme qui facilite la connexion et l'automatisation des processus entre applications cloud et on-premise. Ce service est conçu pour créer des ponts entre différents systèmes, permettant une intégration point à point.
L'iPaaS se distingue par sa simplicité d’utilisation, permettant d’intégrer divers systèmes de manière bidirectionnelle sans aucun code. La simplicité d’utilisation est souvent citée comme un avantage concurrentiel des iPaaS.
Les iPaaS sont programmés de telle sorte qu’un déclencheur spécifique dans un outil entraîne une réponse spécifique dans un autre. Par exemple, le dépôt d’un formulaire Hubspot sur le site internet peut envoyer un message à une personne spécifique sur Slack.
Les iPaaS permettent de créer des workflows, avec plusieurs couches et / ou dépendances.
⚠️ Attention cependant, les workflows peuvent vite devenir complexes s’ils font intervenir un grand nombre de plateformes / de dépendances.
Comparaison des fonctionnalités principales entre un Reverse ETL et un iPaaS
Intégration des données
Le Reverse ETL et l'iPaaS facilitent tous deux l'intégration des données entre diverses plateformes, mais de manière distincte.
Le Reverse ETL se concentre sur le transfert de données d’un data warehouse vers les applications finales, utilisant une approche “déclarative”. Concrètement, cela signifie que vous précisez à votre Reverse ETL la destination que vous souhaitez atteindre (par exemple, Meta Audiences) et celui-ci utilise un connecteur pré-construit pour transférez votre donnée de votre data warehouse vers votre plateforme finale.
L'iPaaS, en revanche, permet une intégration bidirectionnelle (d’un point A vers un point B) et adopte une approche plus “impérative”, basé sur des conditions “SI / ALORS”. Concrètement, cela signifie que vous devez donner toutes les instructions nécessaires pour que votre donnée transite d’une plateforme A à un plateforme B : les conditions de déclenchement, toutes les étapes intermédiaires, la destination finale.


iPaaS vs. Reverse ETL
Cette différence fondamentale souligne la spécialisation du Reverse ETL dans le traitement des grandes quantités de données, spécifiquement avec un grand nombre d’applications. Plus les outils à connecter sont nombreux, plus les flux à définir sont importants, plus il est compliqué de s’assurer de l’exhaustivité des connections. C'est la raison pour laquelle Boomi vient de racheter Rivery.
L'iPaaS, de son côté, excelle dans la gestion de flux de données en temps réel entre divers systèmes : dès qu’un élément déclencheur arrive, la donnée est envoyée à un autre outil.
Automatisation des flux de travail
Tandis que les deux technologies automatisent les transferts de données, l'iPaaS offre des interfaces visuelles no-code qui facilitent la création de workflows.
⚠️ Le Reverse ETL peut exiger une compréhension plus technique, bien que sa nature spécialisée soit précieuse pour des applications spécifiques. Par ailleurs, tous les types de Reverse ETL n’offrent pas d’interface no-code, pouvant compliquer la création des flux de travail pour des équipes moins techniques.
Gestion de la qualité des données
Les deux approches incluent des fonctions de nettoyage et de validation des données. Cependant, le Reverse ETL offre des capacités supérieures dans la gestion des exceptions et la correction d'erreurs.
Parce que la donnée est transférée en lot (et non après un déclencheur spécifique et point par point), la Reverse ETL offre une gestion plus robuste des pipelines de données. En cas d'erreur de mapping, un utilisateur peut rapidement identifier les changements de configuration à effectuer, revenir à un état antérieur et même resynchroniser toute la donnée qui aurait du transiter vers une destination en quelques clics.
Avec une multiplication des flux côté iPaaS, il est souvent plus complexe de comprendre d’où provient l’erreur. Par ailleurs, les données qui auraient du transiter mais qui n’ont pas bougées à cause d’une erreur de configuration doivent généralement être ré-importées manuellement.
👉🏼 Cette capacité à gérer la qualité de grands volumes de données avec précision fait du Reverse ETL un choix privilégié pour des opérations nécessitant une fiabilité élevée.
Sécurité et conformité
Bien que les deux plateformes soient conformes aux normes de sécurité et de régulation, l'iPaaS, de par sa nature connective, peut nécessiter une attention plus soutenue à la sécurité. La gestion des multiples points de contact peut complexifier la surveillance de la sécurité. L’iPaaS fonctionne comme une “boite noire”, soulevant des problèmes de gouvernance.
Cette complexité peut nécessiter des stratégies de sécurité plus élaborées pour l'iPaaS comparativement au Reverse ETL.
Scalabilité et performances
Le Reverse ETL se distingue par sa flexibilité architecturale, gérant efficacement de grandes quantités de transactions de données en temps réel. L'iPaaS, bien que flexible, peut impliquer des coûts supplémentaires avec chaque nouvelle intégration.
Cette différence de coût et de gestion rend le Reverse ETL plus attrayant pour les entreprises traitant de grandes quantités de données de manière régulière.


Table de comparaison : Reverse ETL vs. iPaaS
Comment choisir entre un iPaaS et un Reverse ETL ?
En général, au fur et à mesure que votre architecture IT et vos équipe data et marketing évoluent, il deviendra de plus en plus onéreux de s'appuyer uniquement sur des solutions iPaaS. Le Reverse ETL permet de gérer de plus grand volume de données, le tout de manière centralisée et plus sécurisée. En se basant sur une source unique de vérité, le data warehouse, le Reverse ETL offre une efficacité opérationnelle et une cohérence des données que les solutions point à point ne peuvent égaler.
Pour savoir si le moment est venu pour vous de passer d’un iPaaS à un Reverse ETL, posez-vous les bonnes questions :
Architecture IT : Quelle est ma source unique de vérité aujourd’hui ? Les données client sont-elles déjà centralisées dans un data warehouse ?
Équipe data : Combien d'employés travaillent sur l’architecture data et/ou les opérations ? Peuvent-ils m’aider à construire un data warehouse ? Vont-ils à prendre en main un Reverse ETL ?
Stack marketing : Combien d’outils marketing sont-ils aujourd’hui utilisés ? Comment ce chiffre est amené à évoluer dans les années à venir ? Une solution point-à-point peut-elle être facilement paramétrable par quelqu’un en interne ?
Cas d’usage : Ai-je d’ores et déjà identifié des cas d’usage d’activation de la donnée ? Comment besoin évolueront-ils dans les mois / années à venir ?
Si vous voulez tester notre Reverse ETL gratuitement, remplissez ce questionnaire !
👇
Testez gratuitement notre Reverse ETL !
Conclusion
Le choix entre Reverse ETL et iPaaS dépend fortement des besoins spécifiques d'intégration et de gestion des données d'une entreprise. Les entreprises doivent évaluer leur volume de données, la fréquence des transactions et les exigences de sécurité pour choisir l'outil le plus adapté.
Prenez le temps de définir clairement vos besoins avant de sélectionner la technologie qui optimisera vos opérations et soutiendra votre croissance. Pensez à la scalabilité, à la sécurité et à la complexité de gestion avant de prendre une décision.
Si vous voulez en savoir plus à propos des Reverse ETL, contactez-nous !