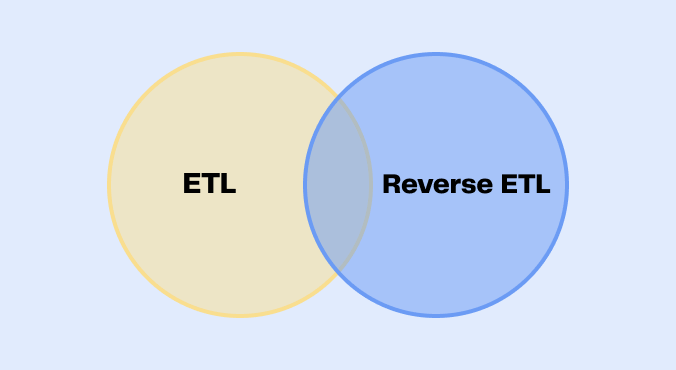


L’ETL et le Reverse ETL sont deux approches distinctes pour gérer les flux de données dans une organisation. Comprendre leurs différences est crucial pour choisir la méthode la plus adaptée à vos besoins en matière de gestion de données.
Ne vous inquiétez pas, il est normal que vous puissiez avoir besoin des deux outils pour couvrir tous vos cas d’usage !
Définitions des ETL et Reverse ETL
À quoi correspond l’ETL ?
L'ETL (Extract, Transform, Load) est un processus de gestion des données, qui se décompose en trois étapes principales :
Extract (Extraction) : Récupération des données à partir de diverses sources (bases de données, fichiers, API, etc.).
Transform (Transformation) : Nettoyage, modification et vérification et tri des données pour les adapter à un format ou une structure cible, souvent pour des analyses ou des rapports*.* L’objectif est de standardiser les données et de les rendre exploitables par n’importe qui dans l’entreprise, notamment pour du reporting.
Load (Chargement) : Insertion des données transformées dans un système de stockage final, comme un data warehouse ou une base de données cible.
L'ETL est crucial pour l'intégration des données et la prise de décision basée sur des informations consolidées et préparées.


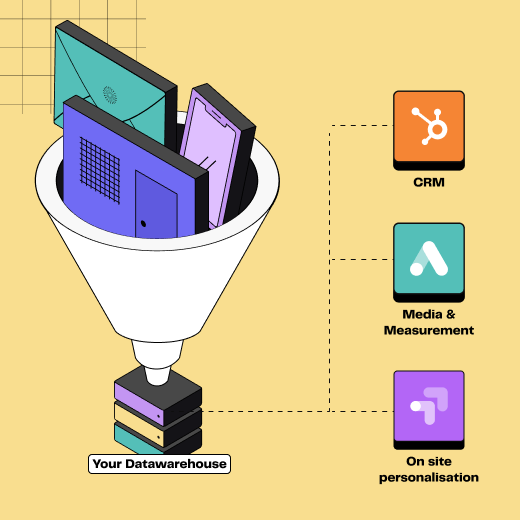
Illustration du processus Extract Transform Load
De plus en plus, les données sont extraites, puis chargées dans un data warehouse cloud, pour finalement y être transformées. Ce processus s’appelle l’ELT (Extract, Load, Transform). Le processus ELT est souvent désigné comme une approche préférable pour la gestion des données, car il permet de conserver toutes les données brutes dans le data warehouse, jusqu'à ce qu’elles soient exploitées.
À quoi correspond le Reverse ETL ?
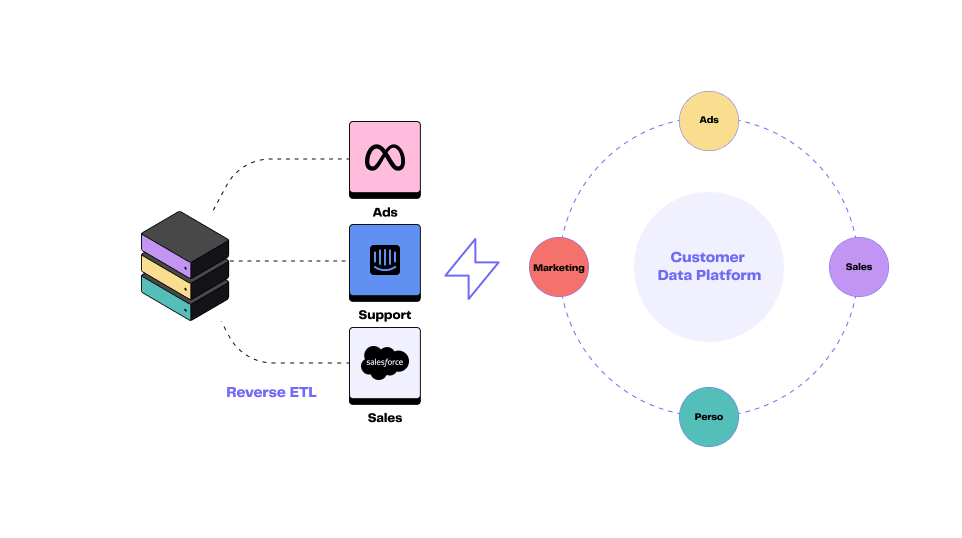
Le Reverse ETL est le processus inverse de l’ETL. Il s'agit d'extraire des données depuis une source centralisée (souvent, un data warehouse), de les transformer pour les adapter aux systèmes opérationnels et de les charger dans des applications métiers.
Le Reverse ETL se concentre sur la distribution des données analytiques vers des systèmes opérationnels pour améliorer les processus métiers, parfois même en temps réel.


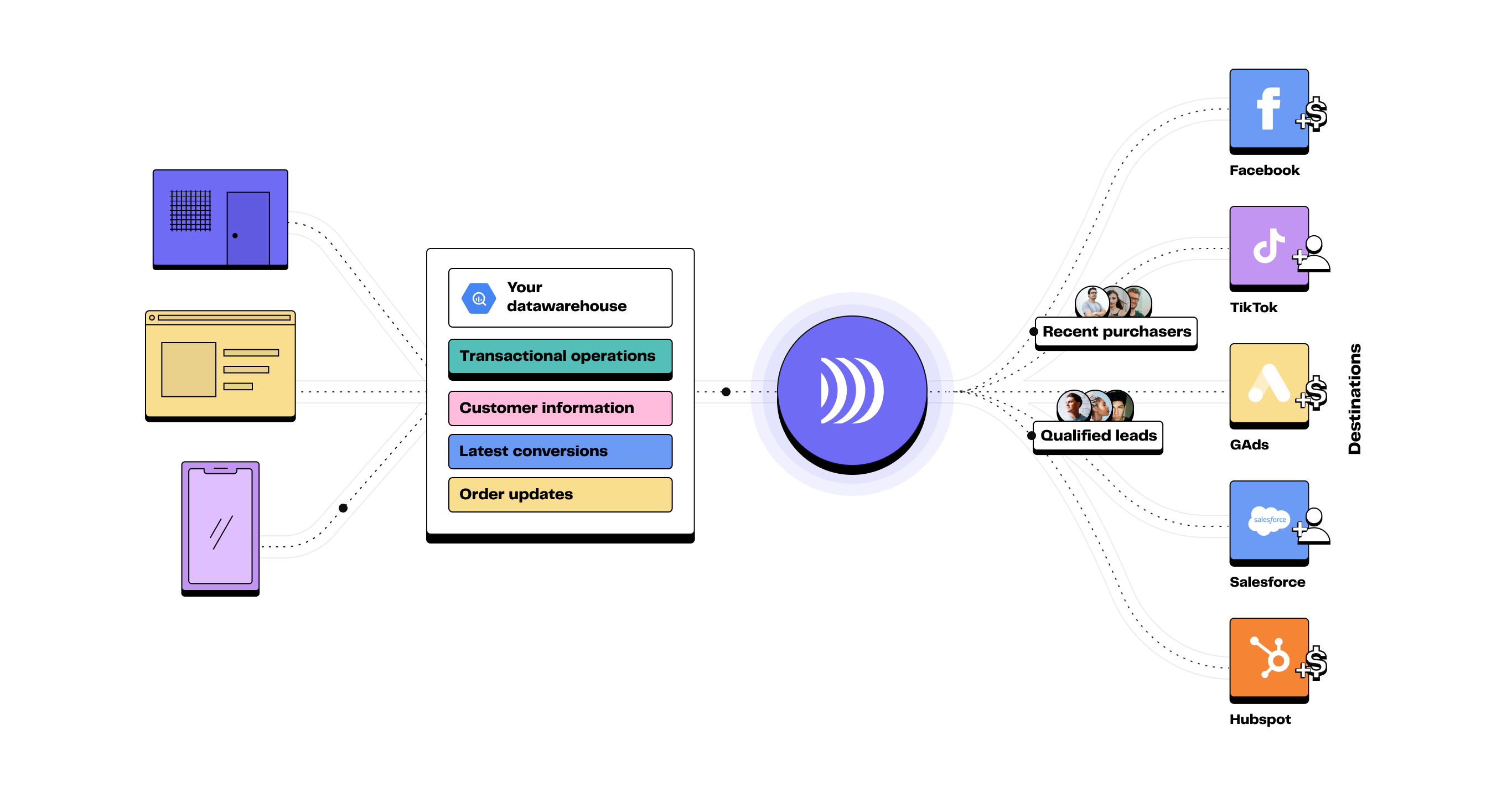
Illustration du processus Reverse ETL
Dans la suite de cet article, nous nous intéressons aux différences fonctionnelles des ETL et des Reverse ETL.
Flux de données
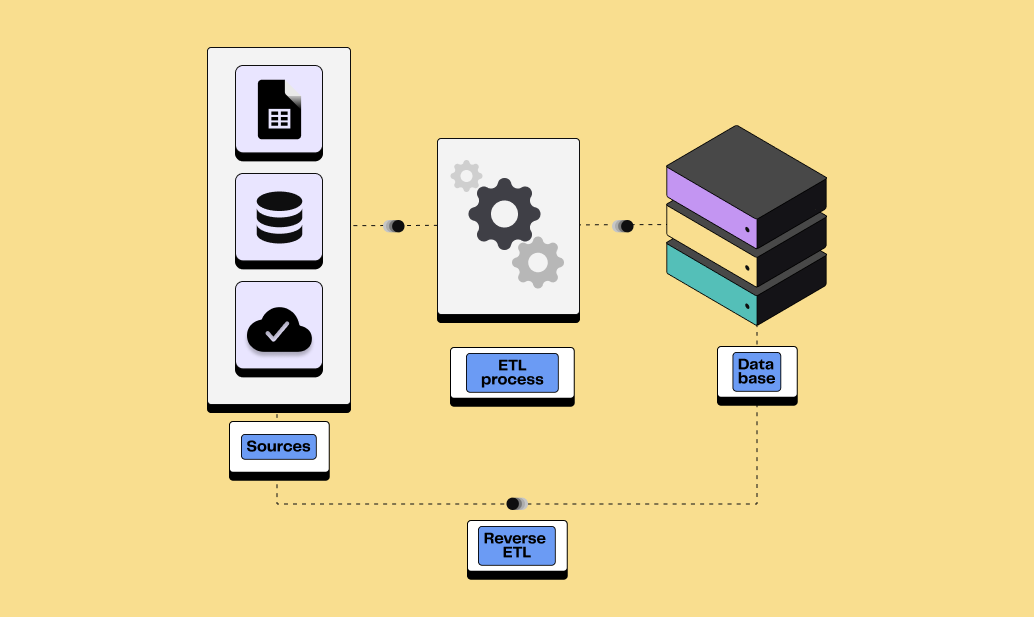
La principale différence entre ETL et Reverse ETL réside dans la direction du flux de données.
L’ETL extrait les données des systèmes sources (comme les bases de données transactionnelles, les fichiers csv, etc.), les transforme selon les besoins de l'analyse, et les charge dans un data warehouse.
Le Reverse ETL, quant à lui, transfère les données d'un data warehouse vers des outils métiers tels que les CRM, les systèmes de marketing et les plateformes d'analyse.
Cette distinction est fondamentale car elle détermine le point de départ et la destination des données dans votre infrastructure technologique.

Objectifs et utilisation
L'ETL traditionnel se concentre sur la consolidation et l'analyse des données, fournissant une vue unifiée et historique des activités de l'entreprise pour soutenir les décisions stratégiques.
Le Reverse ETL vise à rendre les données centralisées disponibles pour les équipes opérationnelles, permettant ainsi une utilisation plus efficace et directe dans les opérations métiers quotidiennes.
Ces différences d'objectif influencent directement la manière dont les données sont traitées et utilisées au sein de l'organisation.
Complexité de la transformation
Le niveau de complexité des transformations appliquées aux données varie entre ETL et Reverse ETL.
L’ETL traditionnel implique souvent des transformations complexes pour standardiser, dédupliquer, nettoyer et structurer les données provenant de sources disparates avant de les charger dans le data warehouse. Ces différentes opérations transforment des volumes importants de données brutes et inutilisables en données exploitables, notamment pour du reporting.
Le Reverse ETL, en revanche, applique généralement des transformations simples et directes, adaptées aux besoins opérationnels spécifiques des outils métiers. L’objectif principal est d’avoir des données directement exploitables par les équipes métiers (segmentées, au format adéquat, assurant un taux de matching important dans leurs outils, etc.), sans qu’elles n’aient à déranger les équipes data.
Cette différence affecte le temps et les ressources nécessaires pour chaque type de processus.
Temps de latence
Le temps de latence, ou le délai entre l'extraction des données et leur disponibilité pour l'utilisateur final, est un autre aspect clé qui distingue Reverse ETL et ETL traditionnel.
Le ETL traditionnel peut impliquer une latence plus élevée en raison de la complexité des transformations et du volume des données traitées.
Le Reverse ETL tend à offrir une faible latence, quasi en temps réel, permettant aux utilisateurs d'accéder rapidement aux données actualisées pour des actions immédiates dans leurs outils.
Public cible
Enfin, les utilisateurs finaux de Reverse ETL et ETL traditionnel diffèrent généralement au sein de l'organisation.
Le ETL traditionnel est destiné aux analystes ou aux data scientists, qui utilisent les données consolidées pour des analyses approfondies et des rapports stratégiques.
Le Reverse ETL s'adresse principalement aux équipes opérationnelles, comme le marketing, les ventes et le support client, qui ont besoin de données en temps réel pour leurs activités quotidiennes. Pourtant, toutes les solutions de Reverse ETL ne sont pas exploitables par les équipes métiers car des fonctionnalités no-code ne sont pas toujours disponibles.


Comparaison des catégories de Reverse ETL
Pour améliorer votre gestion des données et répondre aux besoins spécifiques de votre organisation, pensez à compléter votre stack technique avec des outils de type ETL et Reverse ETL !
💡 Si vous êtes prêt à optimiser l’analyse et l’activation de vos données, commencez dès maintenant à explorer les outils et les meilleures pratiques d’ETL et Reverse ETL. Pour cela, n’hésitez pas à nous contacter.