









Chez DinMo, notre mission est de démocratiser l'accès et l'utilisation des données clients pour les utilisateurs non techniques (marketing, sales, support, etc.). Nous sommes persuadés que les équipes data doivent se concentrer sur leurs tâches principales sans être distraits par les besoins opérationnels des équipes métiers. Cependant, pour que cela soit possible, ces équipes doivent avoir les outils nécessaires pour exploiter les données de manière autonome, sans dépendre des équipes data.
Le Knowledge Store de DinMo
L'année dernière, nous avons lancé notre première version de notre modèle de données avec cette vision en tête. L'idée était de contourner les modèles de données rigides des CDP traditionnelles en offrant quelque chose de flexible et adapté à toute entreprise. Notre précédent Knowledge Store a été développé en gardant à l'esprit la modern data stack, en suivant une approche de data mesh, s'intégrant parfaitement à l'infrastructure de données existante des entreprises.
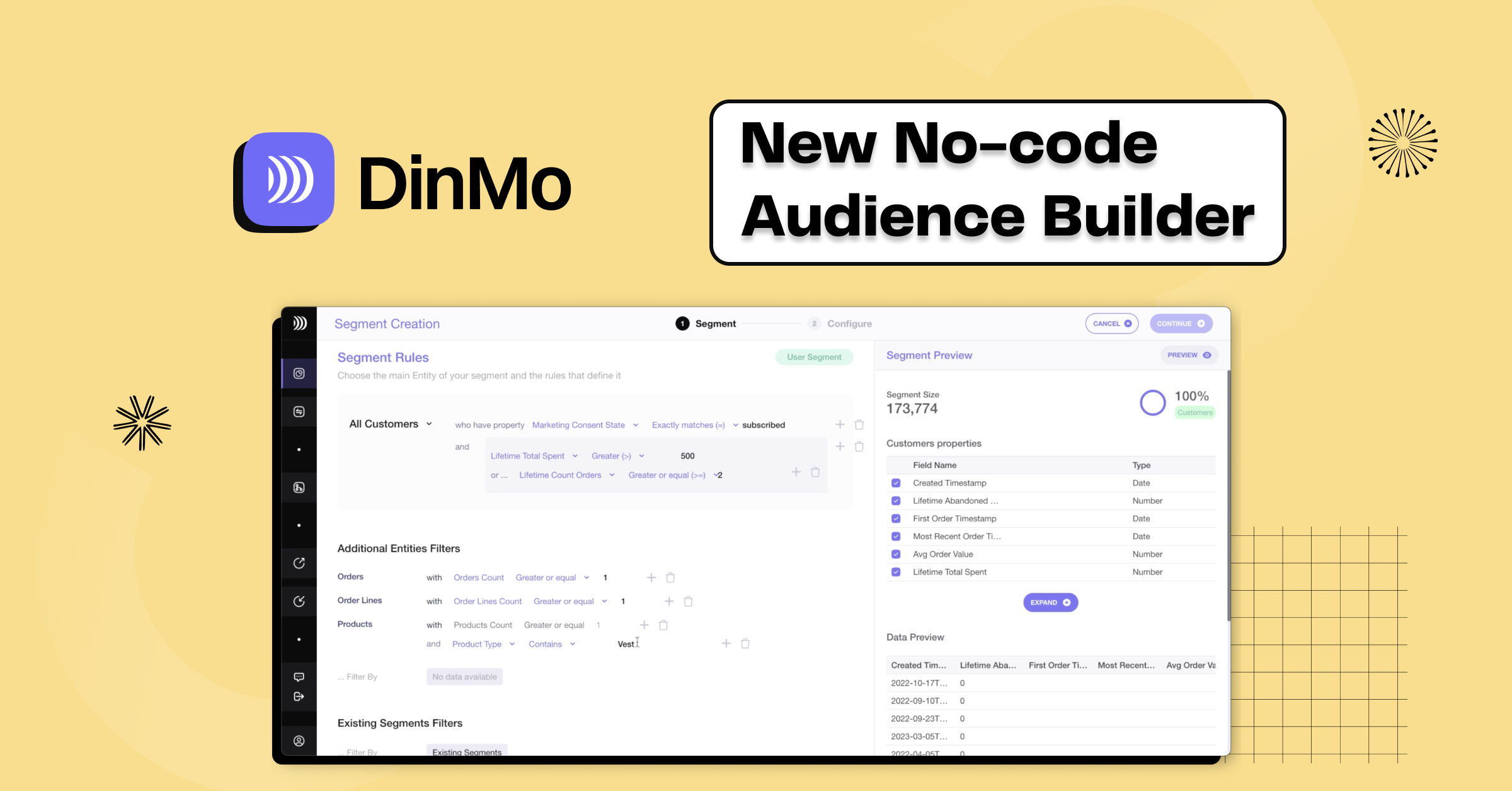
Lors de l'implémentation, les équipes data créaient des Entités une fois, spécifiant à DinMo quelles données devaient être disponibles, comment les interpréter, et comment les afficher de manière conviviale pour les utilisateurs opérationnelles. Après cette configuration initiale (qui prend un maximum d'une heure), les utilisateurs pouvaient utiliser les données de manière autonome avec notre Audience Builder, sans avoir besoin de l'implication de l'équipe technique.


Segment Builder intuitif
Le pouvoir de nos entités résidait (et résidera toujours) dans la capacité à exploiter les relations qui existent entre eux. Basées sur vos entités, les conditions de segment peuvent tirer parti de ces relations, offrant une nouvelle dimension de segmentation possible. Les modèles facilitent l'exploration de données multidimensionnelles, permettant d'approfondir la segmentation avancée basée sur les aspects relationnels des données.
Élargissement de notre modèle de données
Au cours des derniers mois, nous avons introduit de nombreuses nouvelles intégrations, certaines soutenant des cas d'utilisation uniques que nous n'avions pas anticipés à l'époque, comme la synchronisation des données d'entreprises avec HubSpot et des informations produits avec Intercom. Bien que notre précédent modèle de données gérait efficacement les synchronisations d'audiences et de conversions, il n'était pas adapté à ces nouveaux scénarios.
Support de nouveaux types d'objets
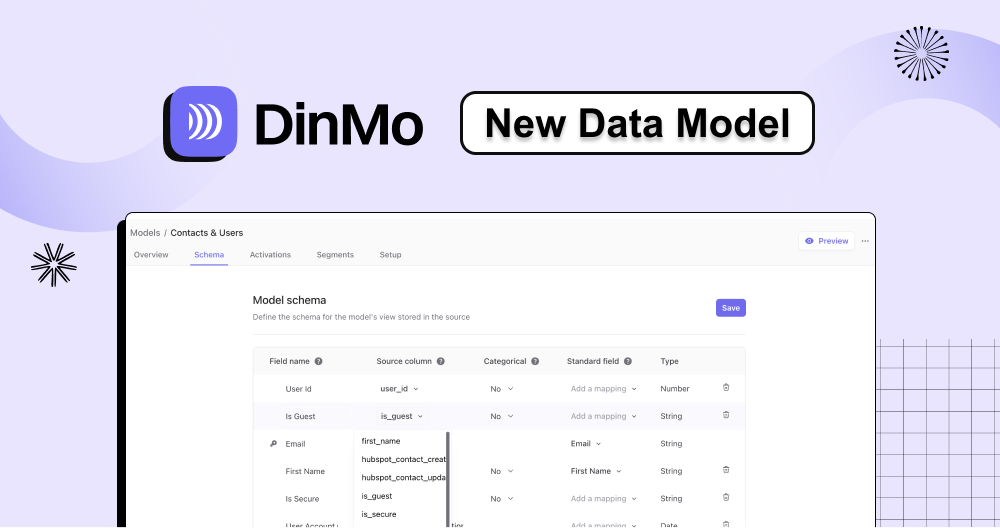
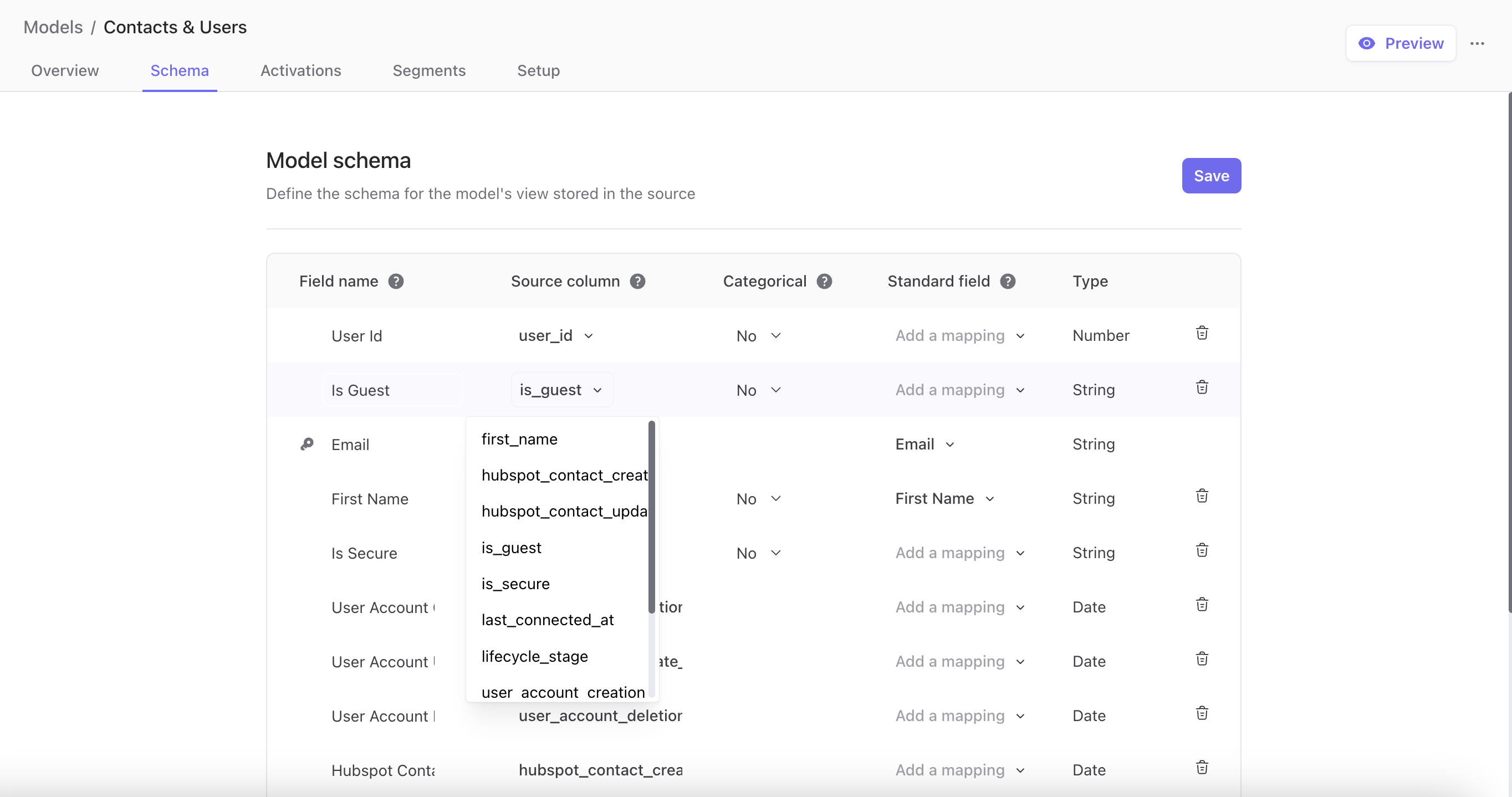
Pour répondre à ces nouveaux cas d'utilisation, nous avons décidé de remanier notre modèle de données en introduisant un nouvel objet de données, les Modèles, qui remplace nos Entités initiales. Ce changement offre une bien plus grande flexibilité dans les types de données disponibles pour l'activation, tout en maintenant les puissantes capacités de segmentation de notre système précédent.
Concrètement, cela signifie que DinMo peut désormais gérer des données personnalisées pour des cas d'utilisation spécifiques, au-delà des simples audiences et conversions. Cela souligne l'avantage d'utiliser une CDP composable, débloquant de nouveaux cas d'usage propres aux CDP.


Des nouveaux types de modèles sont maintenant disponibles
Simplification du processus d'activation
De plus, le processus d'activation pour les objets qui ne sont pas des audiences clients a également été considérablement simplifié. Au lieu de devoir segmenter une entité parente avant de créer une activation, les modèles peuvent être activés directement en quelques clics. Mais bien sûr, les utilisateurs peuvent continuer à segmenter les modèles en utilisant notre Segment Builder no-code, comme auparavant. La nouveauté est que des segments personnalisés peuvent désormais être définis sur DinMo, élargissant ainsi la portée de notre builder.
Cette simplification est aligné avec notre désir de nous positionner comme un Reverse ETL pour les équipes métier, avec des fonctionnalités faciles à utiliser et sans code.
Gestion des altérations de données
Mais ce n'est pas tout. Suite à la mise en production de l'année dernière, nous avons identifié un scénario spécifique où les équipes data devaient malgré tout intervenir sur DinMo après la mise en place initiale : les altérations de données dans le data warehouse source. Cela se produisait généralement lorsqu'une colonne d'une table utilisée par DinMo était supprimée ou renommée en dehors de DinMo. Désormais, les Modèles ont été conçus avec un schéma fixe indépendant de la table dans le data warehouse pour garantir la continuité du service dans ces cas. En pratique, cela signifie que DinMo détecte directement ces problèmes de source et permet de les corriger en un clic au sein du Modèle concerné, sans avoir à déranger les équipes data.
👉 Lisez la documentation DinMo pour plus d'informations détaillées.
Conclusion
En résumé, DinMo reste engagé dans sa mission de démocratiser l'utilisation des données pour les utilisateurs non techniques. Nous sommes convaincus que l'activation des données est essentielle pour prendre des décisions éclairées pour toutes les équipes opérationnelles.
Reconnaissant les besoins évolutifs de nos utilisateurs, nous avons amélioré notre modèle de données pour accueillir une gamme plus large de cas d'utilisation et offrir une plus grande flexibilité. Et nous prévoyons de continuer dans cette direction. Stay tuned! 🌟
Pour plus d'informations sur nos changements produits, abonnez-vous à notre newsletter !
👇