







Modern Data Stack : Quels sont les meilleurs outils ?
10min • Édité le 17 avr. 2025


Alexandra Augusti
Chief of Staff
La Modern Data Stack (MDS) se compose d'un ensemble de technologies conçues pour permettre la collecte, le stockage, la transformation, l'analyse et la visualisation des données de manière optimale et fiable. Elle s'appuie sur des solutions basées sur le cloud, open source ou intégrées. L’objectif principal de la Modern Data Stack est de garantir une grande flexibilité, scalabilité et efficacité.
Vous envisagez d’élaborer ou d’ajouter des outils à votre Modern Data Stack en 2025 ? Vous êtes au bon endroit !
💡Dans cet article, nous aborderons ce qu'est concrètement une modern data stack, pourquoi elle est cruciale pour exploiter au maximum vos données, et quels outils sélectionner pour répondre efficacement à vos exigences.
Beaucoup de solutions font partie de ce vaste ensemble, mais la Modern Data Stack reste souvent difficile à explorer - tant par son nombre important d’acteurs et de fonctionnalités.
👉🏼 Nous cherchons à mettre en lumière les principales options disponibles sur le marché pour construire votre MDS, classées selon les différentes strates de la modern data stack.
Qu'est-ce que la Modern Data Stack?
La Modern Data Stack (MDS) représente l'arsenal technologique destiné à la collecte, le stockage, le traitement, et l'analyse des données. Chaque brique de la MDS remplit une fonction spécifique et est souvent porté par un outil dédié. Cette modularité assure une meilleure contrôlabilité, facilité de mise en place et scalabilité, car chaque composant peut être adapté ou changé selon les besoins sans impacter l'ensemble du système.
La MDS se décompose en plusieurs briques essentielles, décrites ci-après :
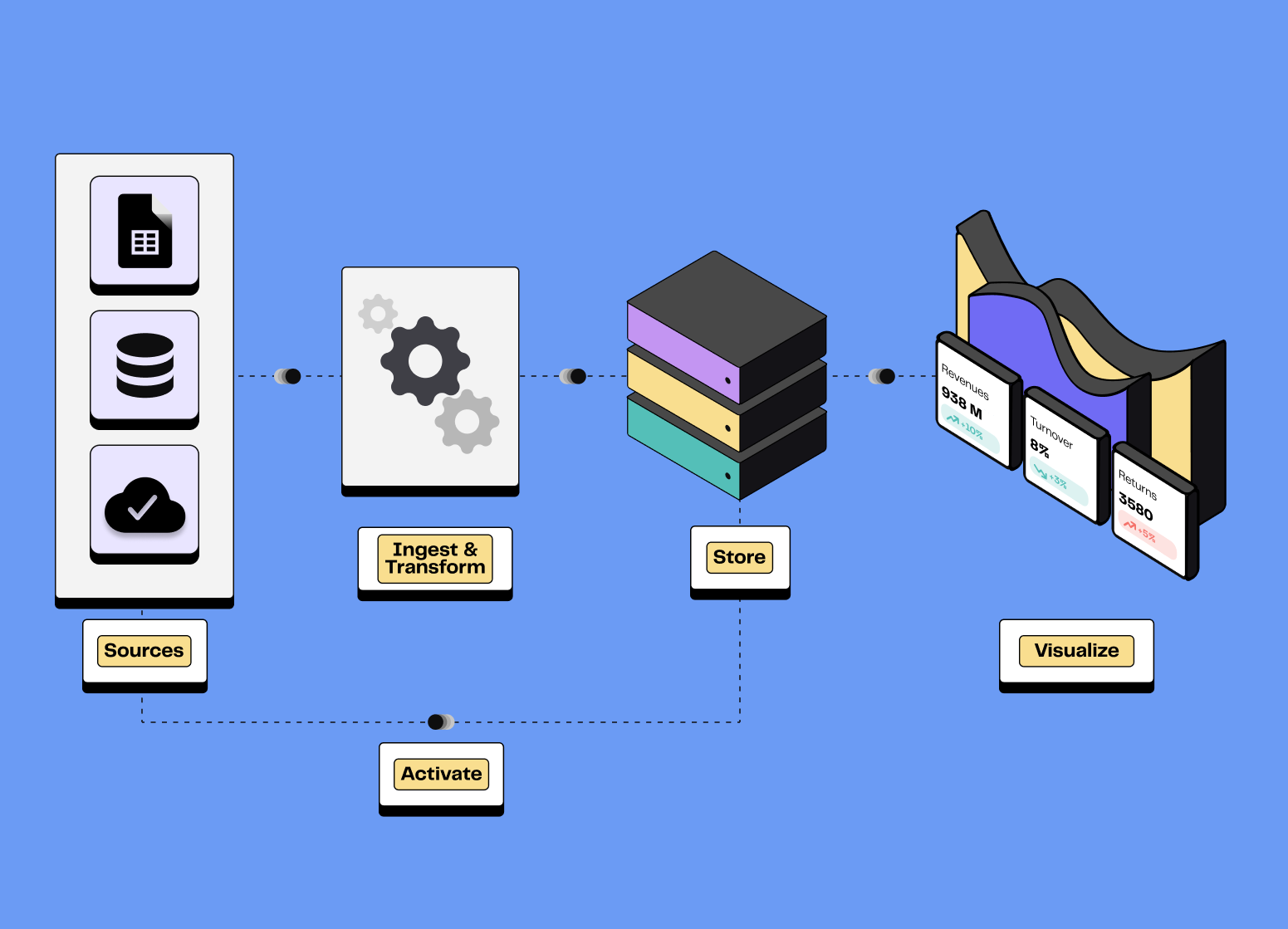
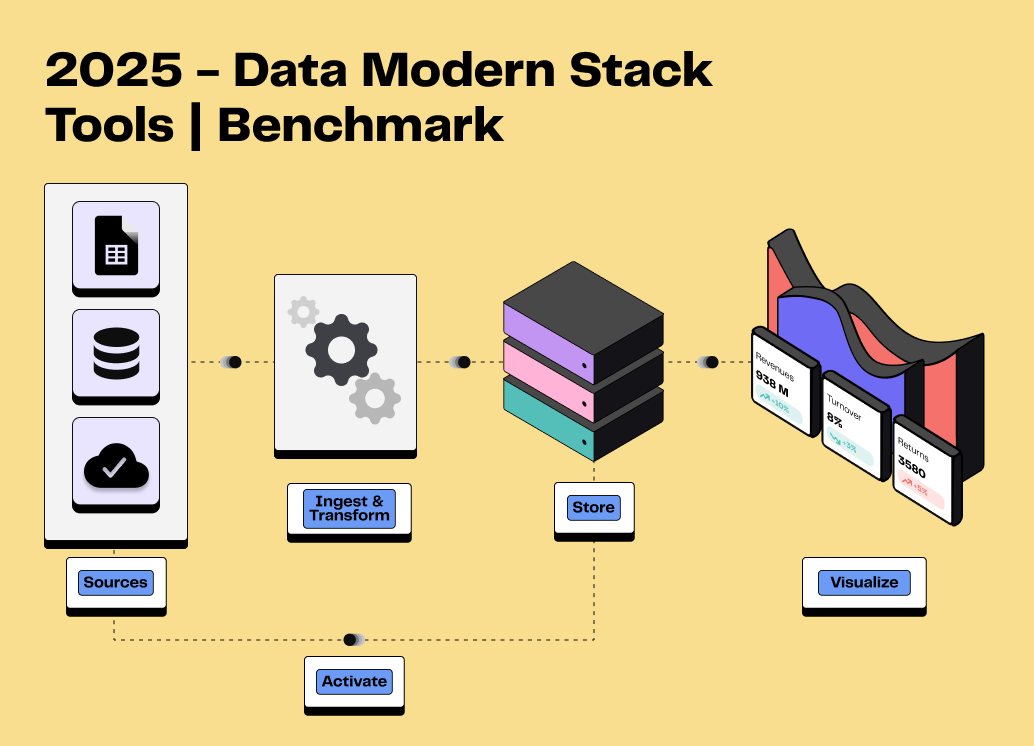
Ingestion de la donnée : L’objectif est de capter les données depuis une multitude de sources, pour les verser dans un système de stockage adapté. On distingue principalement deux méthodes : l'ETL (Extract, Transform, Load) qui transforme les données avant leur chargement et l'ELT (Extract, Load, Transform) qui propose de charger les données d'abord avant de les transformer.


Illustration du processus Extract Transform Load
Stockage de la donnée : Plusieurs options existent, que ce soit les data warehouses, les data lakes ou les bases de données, chacun répondant à des besoin spécifiques en matière de structuration des données. Les solutions modernes de stockage de données se basent largement sur le cloud, garantissant ainsi scalabilité, performance et réduction des coûts.
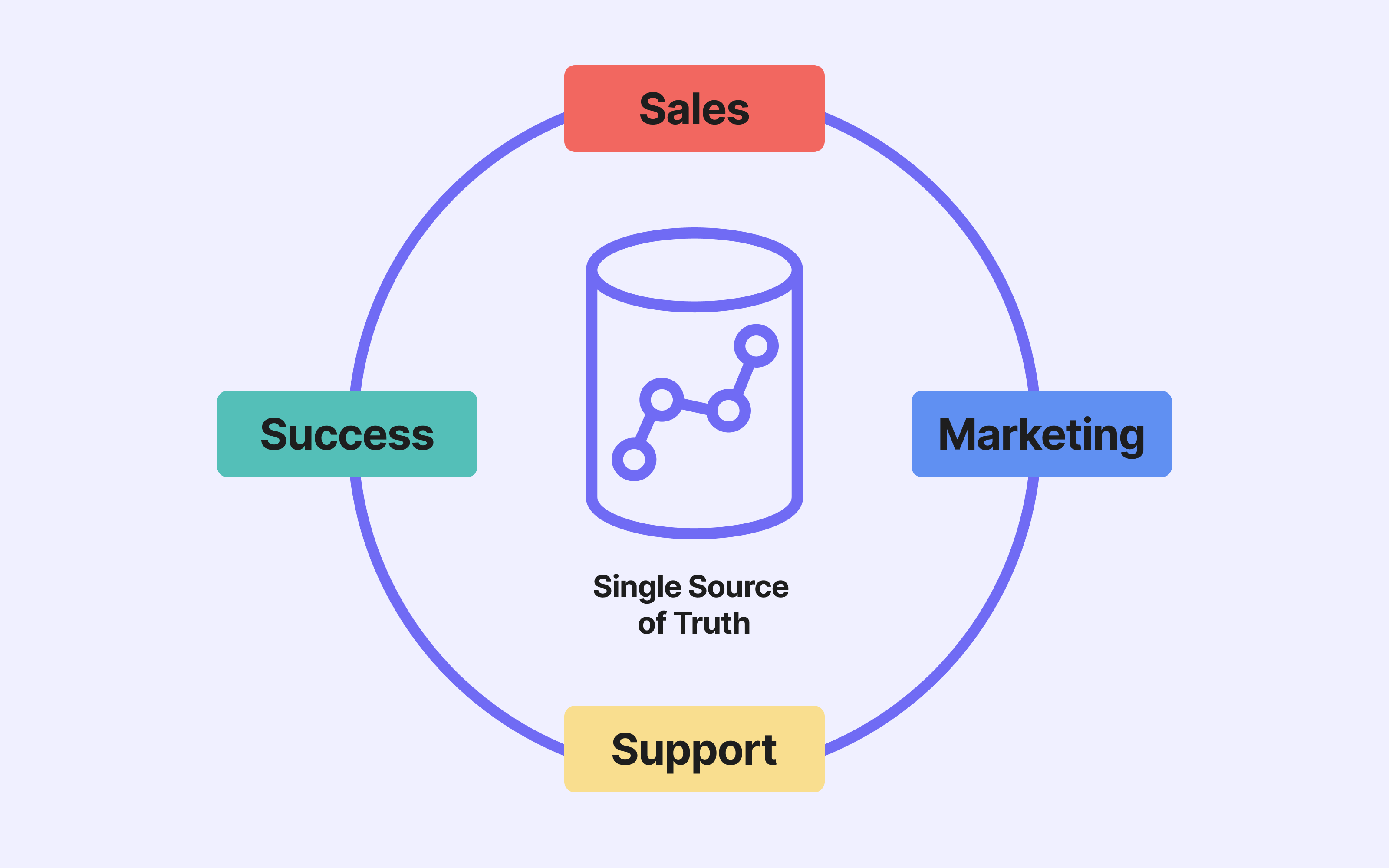
💡 Nous recommandons d'utiliser votre data warehouse comme source unique de vérité.
La transformation de la donnée et l’orchestration : La data transformation vise à nettoyer, enrichir et réorganiser les données pour les rendre exploitables par l’analyse et la visualisation. Quant à la data orchestration, elle automatise et coordonne les étapes de transformation des données et leur déplacement au sein des composants de la MDS.
Business Intelligence : C'est l'ensemble des procédés et des outils permettant d'explorer et de visualiser les données, de générer des rapports et des tableaux de bord, et finalement de produire des insights aider à la prise de décision.
L’activation de la donnée (autre que BI) : Pouvoir utiliser sa donnée dans des outils tiers est aujourd’hui crucial pour répondre aux attentes des clients. La méthode principale correspond au processus de Reverse ETL, envoyant de la donnée segmentée d’un data warehouse vers les outils opérationnels. Les cas d’usages permis par les Reverse ETL sont multiples aussi bien pour les équipes marketing, CRM, commerciales ou de support.


Illustration du processus Reverse ETL
Data Science : Elle englobe les méthodes et outils pour appliquer des processus d’analyse avancée, de statistiques, de machine learning et d'IA aux données, dans le but de créer des modèles prédictifs.
Catalogue de données et gouvernance : Le data catalog permet de documenter, cataloguer et rechercher les données intégrées dans la MDS, offrant un aperçu complet des sources, formats, schémas et utilisations. Parallèlement, la gouvernance des données désigne l'ensemble des normes et processus visant à garantir la sécurité, la conformité et la qualité des données.
Observabilité : Elle concerne la surveillance et le diagnostic des systèmes de données, permettant ainsi d'identifier et de résoudre les incidents et anomalies.
Les principaux acteurs de la Modern Data Stack
Plusieurs acteurs se positionnent sur chaque fonctionnalité de la Modern Data Stack. Il faut cependant noter que certaines solutions cherchent à étendre leur offre et permettent de couvrir plusieurs fonctionnalités.
👉🏼 Nous citons dans cet article les principaux acteurs de chaque brique de la MDS.
⚠️ Disclaimer : cette énumération n'est pas exhaustive, et le paysage technologique recèle d'autres solutions susceptibles de mieux s'accorder à vos besoins spécifiques. Nous mentionnons uniquement les solutions les plus répandues sur le marché et que nous retrouvons chez la plupart de nos clients.
Nous vous encourageons vivement à consulter d’autres ressources, notamment sur les outils spécifiques dont vous pourriez avoir besoin.
Ingestion de la donnée
Airbyte : Avec sa promesse de connexion à plus de 350 sources vers votre data warehouse, votre data lake ou votre base de données, Airbyte séduit par son interface utilisateur intuitive, sa capacité à se déployer à l'horizontale, sa fiabilité et sa simplicité de maintenance. Compatible avec les leaders du stockage de données comme BigQuery, Snowflake, Redshift, etc., Airbyte se caractérise par son aspect open-source, signifiant que n’importe quelle personne de la communauté peut développer un connecteur. Airbyte se positionne comme le choix idéal pour les organisations aspirant à maîtriser leurs flux de données (intégration et réplication) avec une solution modulable et sur-mesure.
Fivetran : Fivetran, logiciel SaaS, assure la connexion de vos sources de données à votre data warehouse en quelques clics. Grâce à son support de plus de 500 sources et à une intégration qui se veut rapide et une sécurité renforcée, Fivetran simplifie radicalement le mouvement de données. Compatible avec les principaux acteurs du stockage, ce service est paré pour les entreprises en quête d'une solution clé en main.
Stitch : Stitch est un outil open source, permettant une connexion de 150+ sources de données à votre data warehouse en quelques minutes. Les intégrations avec le reste de la data stack sont cependant plus limités que les autres outils de data ingestion.
Il existe une multitude d’autres acteurs du marché des ETL ou ELT. Pour choisir l’outil qui correspondra le mieux à vos besoins, prenez en compte plusieurs considérations : le nombre et le type de connecteurs proposés, le niveau de maintenance attendu, la flexibilité et la scalabilité de l’outil et le support offert.
Stockage de la donnée
Les solutions de stockage se déclinent en plusieurs variétés, dont les data warehouses, les data lakes et des solutions hybrides. L’adoption rapide du cloud a fait exploser les cloud data warehouses :
BigQuery : Proposé par Google, BigQuery est un entrepôt de données cloud qui brille par sa capacité à interroger des données structurées et semi-structurées à grande échelle. Offrant des performances de haut niveau, une scalabilité automatique, un modèle de facturation à l'usage et une intégration étroite avec les services Google Cloud, BigQuery est la plateforme de prédilection pour les entreprises qui veulent plonger dans des données massives et complexes avec une solution robuste. Ce data warehouse est le plus adopté par les entreprises de taille moyenne, notamment pour sa structure de coût avantageuse.
Snowflake : Snowflake se présente comme un entrepôt de données cloud, efficient et souple pour la gestion des données structurées et semi-structurées. En plus du stockage, Snowflake offre également des fonctionnalités d’ingestion de données, d’analyses et de visualisation.
AWS Redshift : Service d'Amazon, Redshift vous permet de stocker et d'interroger vos données de manière rapide et sûre. Connu pour sa constance performance, sa modularité, sa sécurité avancée et son intégration avec AWS, Redshift est le compagnon idéal des entreprises souhaitant analyser de grandes quantités de données dans l’environnement Amazon.
Notre recommendation est simple : si votre stack utilise déjà des produits Google, optez pour Google BigQuery ! Sinon, tournez vous vers Snowflake.
💡 Nous sommes partenaires avec les deux solutions et nous intégrons parfaitement à leurs environnements de données.


DinMo est maintenant un partenaire Tech de Snowflake !
Si vous souhaitez opter pour une solution open-source, vous pouvez vous tourner vers ClickHouse, un système de gestion de base de données OLAP orienté colonnes, réputé pour être rapide. Apache Pinot peut également être une bonne solution open-source
Transformation et orchestration
Ce processus englobe aussi l'automatisation et la coordination de los tâches de transformation, ainsi que l'acheminement des données à travers les différentes composantes de la stack data moderne.
Concernant la transformation des données, dbt est de loin la solution de référence du marché. Solution open source, dbt vous offre la possibilité de transformer vos données directement dans votre data warehouse en utilisant SQL. Sa simplicité, modularité, fiabilité et son approche collaborative font de dbt un choix préférentiel pour ceux qui souhaitent gérer leurs données avec agilité dans les principaux data warehouse.
Dataform, Trifacta ou encore Rockset permettent également de transformer vos données.
En ce qui concerne les outils d’orchestration, nous pouvons notamment citer :
Apache Airflow : Cet outil open source, exploitant Python, permet une orchestration de vos flux de données en lignes de commandes. Avec Airflow, planifier, surveiller et orchestrer vos traitements est simplifié grâce à une approche basée sur des opérateurs, des détecteurs et des UIs clairs. Airflow est réputé pour sa grande flexibilité et est la solution de référence du marché. Astronomer est une sur-couche d’Apache
Dagster : Dagster est un orchestrateur de données, fournissant un cadre pour construire, tester et déployer des data pipelines. Il s’agit d’une bibliothèque open source pour la création de systèmes comme les processus ETL et les pipelines de Machine Learning.
Business Intelligence
Les outils de BI sont essentiels pour permettre aux entreprises d’analyser leurs performances et de prendre des décisions data-driven. Il existe un grand nombre d’acteurs sur le marché, parmi les plus connus :


Magic Quadrant de Gartner récapitulant les acteurs BI
Nous souhaitions développés les plus répandus parmi nos clients :
Power BI : Power BI, développé par Microsoft, est reconnu pour ses fonctionnalités puissantes, sa flexibilité et sa connexion avec l’environnement Microsoft. La courbe d’apprentissage peut être plus importante pour les fonctionnalités avancées. Power BI propose des fonctionnalités AI et ML intégrées. PowerBI est leader du marché, notamment sur le segment des grandes entrerpises.
Looker : Looker Studio, partie intégrante de l’écosystème Google, se distingues par sa simplicité d’utilisation et son intégration avec toutes les solutions Google (BigQuery notamment, mais aussi Google Analytics pour les analyses marketing). Il propose un générateur de visuels en drag and drop. A cause de sa simplicité, Looker peut être limité dans les visualisations proposées.
Tableau : Tableau est un outil de data visualization appartenant au groupe Salesforce, permettant de simplifier les données brutes en les convertissant dans un format compréhensible. Il permet l’analyse rapide de données et la génération de visualisations sous forme de tableaux et de tableurs.
Pour de la visualisation uniquement, vous pouvez également vous tournez vers Metabase, qui est très simple à prendre en main et qui permet de créer des dashboards en quelques minutes. Surtout, le pricing de Metabase est très intéressant !
Activation de la donnée
Nous avons écrit un article dédié pour comparer les principaux Reverse ETL.
On distingue plusieurs catégories de Reverse ETL :
Les outils dédiés uniquement à l’intégration de la donnée (Rivery par exemple)
Les outils de Reverse ETL généralistes, qui sont plutôt utilisés par les équipes data (Hightouch par exemple)
Les outils de Reverse ETL pour les équipes métiers, qui libèrent du temps aux équipes data et rendent autonome les équipes marketing (comme DinMo par exemple).


Comparaison des catégories de Reverse ETL
Data Science
Cette discipline ouvre la voie à l'innovation et la résolution de défis complexes, avec des outils conçus pour simplifier le développement et le déploiement de solutions de data science :
dataiku : Daitaku est une plateforme qui simplifie le travail de préparation de donnes et la mise en place de modèles de Data Science. La solution est idéale pour les projets où personnalisation et flexibilité sont de mise.
DataRobot : DataRobot est une solution pour ceux qui désirent mettre en œuvre rapidement des modèles de machine learning et d'IA sans sacrifier la qualité ou la compréhension des résultats. DataRobot porte une attention particulière à la gouvernance des modèles et à la conformité.
A noter que Databricks est une plateforme complète en sur-couche de votre data warehouse avec des fonctionnalités Analytics et Data Science avancées.
Data Catalogue et Gouvernance
Ces étapes cruciales s'appuient sur des outils dédiés à la création et la gestion d'une documentation claire et accessible :
Atlan : Atlan redéfinit la gestion du catalogue de données en favorisant une approche collaborative. Une solution pensée pour ceux qui cherchent à impliquer activement leur équipe dans la gouvernance des données. Il propose des fonctionnalités de catalog, quility, lineage, exploration, etc.
Alation : Alation est un outil de catalogue de données de premier plan qui offre une interface conviviale et des fonctionnalités robustes pour aider les organisations à tirer parti de leurs données. Grâce à ses capacités de recherche alimentées par l'IA et à sa gestion étendue des métadonnées, Alation permet aux utilisateurs de découvrir et de comprendre facilement les actifs de données.
Castordoc : Intuitif et simple, Castordoc propose une gestion de data catalogue à la portée de tous. Un outil économique pour les entreprises souhaitant mener leur projet de catalogage sans complexité.
Data Quality & Observability
La qualité et l'observabilité des données marquent la dernière brique de la modern data stack, visant l'assurance d'une base de décision solide à travers des données fiables et performantes.
Ces outils permettent une gestion précise des indicateurs de qualité et d'observabilité des données :
Monte Carlo : Monte Carlo offre une vue proactive sur la santé de vos données et pipelines, grâce à une observabilité accrue. Monte Carlo utilise l’intelligence artificielle pour surveiller, identifier et corriger les problèmes de qualité des données.
Great Expectations : Great Expectations est un autre outil populaire d'observabilité des données qui se concentre sur la validation et l'intégrité des données. Il aide les organisations à définir et à mettre en œuvre les attentes en matière de qualité des données, garantissant ainsi des données fiables et cohérentes.
Conclusion
La Modern Data Stack représente une évolution majeure dans la manière dont les entreprises gèrent et utilisent leurs données, offrant une gestion plus efficace, flexible et rentable. Dans un écosystème évoluant rapidement, un besoin constant d'adaptation et d'évolution règne, mais les avantages potentiels pour une entreprise sont énormes.
Si vous avez des questions supplémentaires concernant la MDS et notamment l'activation de la donnée, n'hésitez pas à nous contacter !
💡 Si vous avez besoin d’experts pour les construire votre Modern Data Platform, vous pouvez contacter notre partenaire Modeo.
Si vous souhaitez voir une autre entreprise listée dans ce benchmark, n'hésitez pas à m'envoyer un email. Je serais heureuse d'avoir votre feedback et de prendre en compte vos recommendations : alexandra@dinmo.com