








Tout savoir sur l’observabilité des données
7min • Édité le 7 févr. 2025


Olivier Renard
Content & SEO Manager
Selon Gartner*, les données de mauvaise qualité coûtent en moyenne 12,9 millions $ par an aux entreprises. Pourtant, moins de la moitié d’entre elles en mesure réellement l’effet.
Dans un contexte où les décisions stratégiques reposent sur des données fiables, la data observability (DO) en garantit l’intégrité et la précision.
Les points clés :
La data observability vise à assurer l’accessibilité et la fiabilité des données. Elle aide à repérer et corriger les erreurs pour éviter les décisions basées sur des informations erronées.
Elle surveille en continu la santé des flux de données, ce qui la distingue du data quality management.
Différents outils spécialisés facilitent sa mise en œuvre. Ils permettent de superviser la qualité des données à grande échelle.
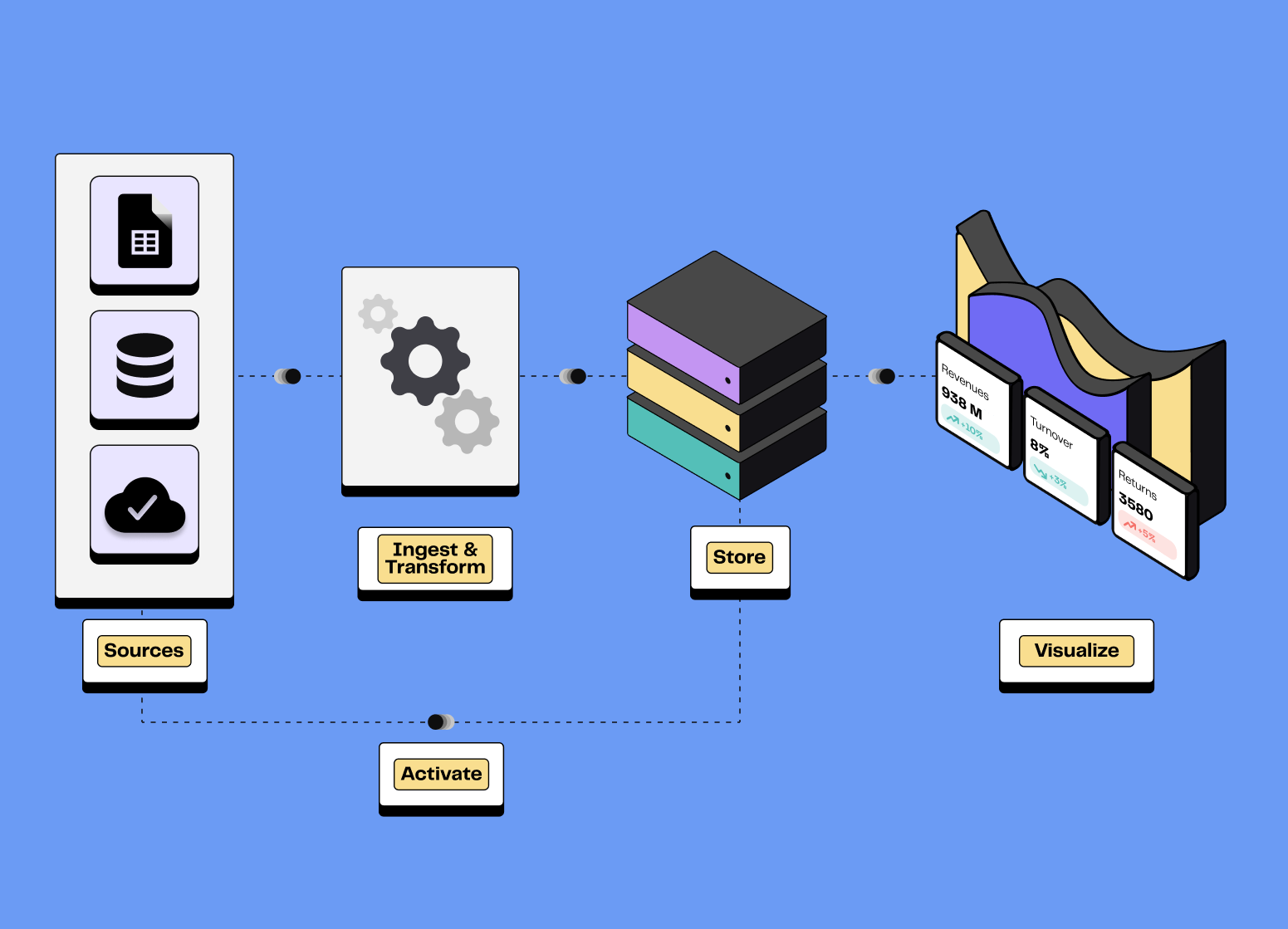
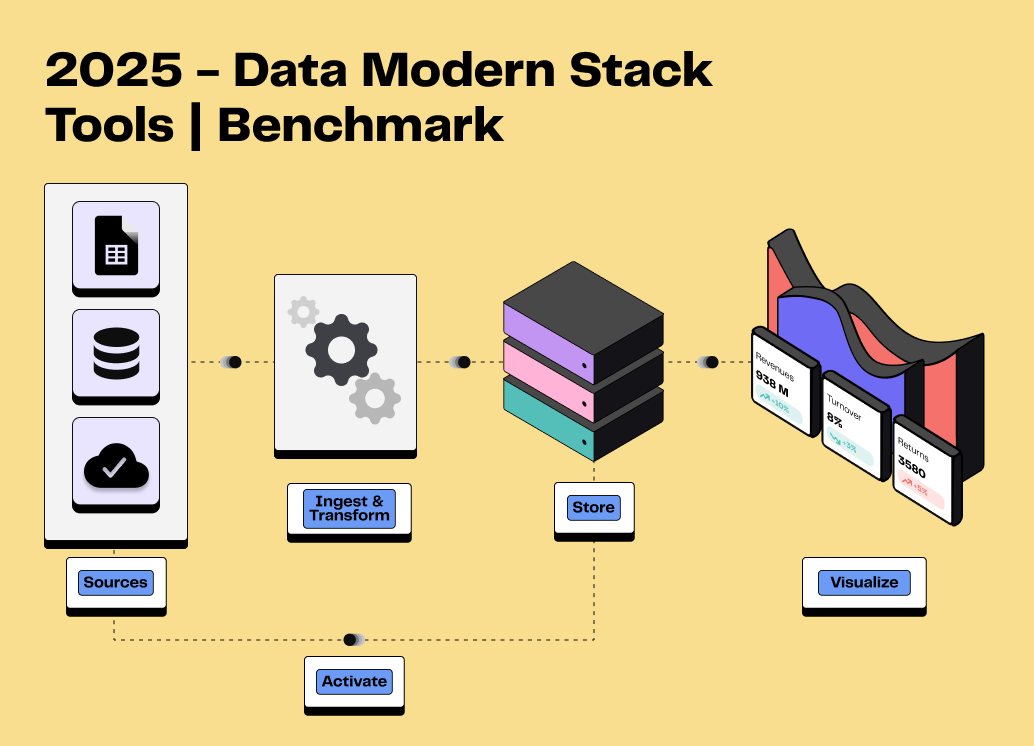
Composante essentielle d’une Modern Data Stack (MDS), la data observability améliore la performance globale. Des données fiables facilitent la prise de décision, réduisent les coûts et augmentent l'efficacité des équipes.
👉 Découvrez comment la data observability garantit des données fiables et améliore vos décisions stratégiques. Explorez ses principes, ses particularités et les outils pour l’implémenter efficacement. 🔎
Définition et importance de la data observability
La data observability, ou observabilité des données, désigne la capacité à surveiller, analyser et garantir en continu la qualité des données.
Elle permet aux entreprises de détecter les erreurs, d’assurer l'intégrité de l'information et de fiabiliser les décisions stratégiques.
La DO influe sur la performance d’une entreprise et sur sa capacité à faire des choix éclairés :
Effet sur la prise de décision et la cohérence des analyses. En identifiant rapidement les erreurs dans les flux de données, elle prévient les décisions prises sur la base d'une information erronée ou incomplète.
Réduction des risques financiers ou opérationnels liés aux erreurs de données. Elle évite ainsi les perturbations et la perte de confiance. Elle assure également le maintien de la conformité avec les normes de sécurité, de confidentialité et les réglementations.
Amélioration de la précision et de la performance des pipelines de données. Elle identifie les goulots d'étranglement et améliore l'efficacité des processus de traitement. Cela réduit les temps de latence et assure un flux de données constant et fiable.
Observabilité vs Data Quality Management (DQM) : comprendre les différences
Le DQM et l’observabilité visent tous deux à garantir la fiabilité des données. Néanmoins, leurs finalités et périmètres présentent certaines différences.
Data quality management : définition et rôle
Le DQM, en français gestion de qualité des données (GQD), vise à préserver l’intégrité des données tout au long de leur cycle de vie. Il repose sur des contrôles manuels et automatisés pour identifier les doublons, les valeurs manquantes ou les erreurs de format.
Il cherche à maintenir des standards élevés en matière de qualité des données. Les acteurs clés du DQM sont le Data Quality Manager, en charge de la définition des normes, et le Data Quality Analyst, chargé du suivi quotidien.
Data observability : une approche plus globale
La DO offre une vision plus large et proactive, en surveillant en temps réel les pipelines de données.
Cette approche comprend :
Une supervision en continu : suivi constant des mouvements et transformations de données dans l’ensemble des systèmes.
La détection d’anomalies : des alertes permettent d'identifier les erreurs, comme des pics soudains ou des ruptures dans les flux.
Un diagnostic avancé : analyse de l’origine des problèmes pour accélérer leur résolution.
Bien que DO et DQM partagent le même objectif, l’observabilité adopte une approche plus dynamique et automatisée. Elle s'attache à la santé globale de l’écosystème de données.
Elle permet de repérer les incidents avant qu'ils n'impactent les résultats, grâce à une surveillance globale des pipelines. Elle répond aux besoins des entreprises traitant de gros volumes de données dans des environnements complexes.


data quality vs data observability
Comment mettre en place la Data Observability ?
La DO repose sur cinq piliers fondamentaux. Ces dimensions permettent de surveiller la qualité des données sous différents angles, détecter une anomalie et maintenir la performance des systèmes.
Pilier | Définition | Problèmes detectés | Objectif / Impact |
|---|---|---|---|
Fraîcheur | Ce pilier mesure la récence des données. Elle vérifie leur actualisation régulière. | Obsolescence, délais d’actualisation trop longs. | Assurer l'accès à de la donnée récente. |
Distribution | Elle consiste à évaluer le bon accès à la donnée collectée, ainsi que sa validité. | Inaccessibilité, écarts par rapport aux sources fiables. | Maintenir des données représentatives, éviter les biais dans les analyses. |
Volume | Il contrôle la quantité de données collectées par rapport aux attentes. | Fluctuation des volumes, manque d’exhaustivité. | Identifier les incidents de collecte pour maintenir l'intégrité globale. |
Schéma | Il surveille la structure et l’organisation de la donnée. | Modification de structure ou problème d’interconnexion. | Prévenir les erreurs d'intégration et assurer la compatibilité avec les systèmes de traitement. |
Lineage (Traçabilité) | Il consiste à suivre le cheminement d’une donnée depuis sa source jusqu'à son utilisation. | Détérioration à une étape du pipeline, transformations non tracées. | Assurer la traçabilité et la compréhension de l'origine des erreurs pour un meilleur pilotage des flux. |
Les cinq piliers de l'observabilité des données
Les étapes clés d’une stratégie réussie
Pour maintenir des données fiables et exploitables, l’implémentation d'une stratégie de data observability passe par plusieurs étapes essentielles :
Définir ses besoins de supervision : listez les objectifs clés (réduction des erreurs, conformité, optimisation des flux de données) et les indicateurs de performance à suivre.
Identifier les sources de données critiques : listez les bases de données, systèmes de gestion de contenu et outils SaaS stratégiques pour votre activité.
Implémenter des outils adaptés à vos besoins : adoptez des solutions capables de surveiller, diagnostiquer et corriger en temps réel toute anomalie dans vos pipelines.
Former les équipes : sensibilisez les collaborateurs à l'importance de la qualité de la donnée et aux bonnes pratiques d'observabilité.
Outils et technologies
Les critères pour choisir votre solution :
Facilité d'intégration : l'outil doit pouvoir s'intégrer facilement à votre stack data existante (data warehouses, ETL, outils BI).
Fonctionnalités : détection, alerting, analyse, diagnostic, et correction.
Scalabilité et prix : vérifiez si la solution peut gérer des volumes croissants de données tout en restant adaptée à votre budget.
Conformité et sécurité : il faut bien entendu respecter les normes de sécurité et de confidentialité (RGPD, SOC2...).
Les principales solutions du marché :
Monte Carlo
Monte Carlo se distingue par son approche automatisée de la surveillance des pipelines de données. Il propose des alertes intelligentes et une détection proactive des erreurs sur l'ensemble des flux.
Sifflet
Sifflet est apprécié pour sa simplicité d'utilisation et son interface claire. Il met l'accent sur l'analyse des métadonnées et propose une vision complète des pipelines avec des diagnostics détaillés.
Datadog
Datadog est une plateforme complète qui couvre l'observabilité des données, mais aussi celle des infrastructures et applications. Sa force réside dans sa capacité à centraliser la supervision IT et data sur une même interface.
Bigeye
Bigeye offre des fonctionnalités avancées de monitoring et de détection des variations anormales. Il est particulièrement adapté aux environnements avec des flux complexes et volumineux.
A noter qu’il existe beaucoup d’autres solutions sur le marché, qui ont toutes leurs spécificités : Grafana, CastorDoc, Acceldata, Splunk, Dynatrace.
")
Sifflet Data Observability (Source : Sifflet)
Avantages et cas d’usage
La DO favorise la collaboration entre l’équipe data et les fonctions opérationnelles autour d’un objectif commun d’amélioration des flux de données.
Amélioration de la prise de décision
Dans le secteur du e-commerce, des données fiables permettent de prendre des décisions rapides pour personnaliser l’expérience client.
Grâce à la DO, les équipes identifient plus rapidement les erreurs. Elles peuvent ainsi proposer des recommandations produits cohérentes et adaptées sur toutes les plateformes.
Détection proactive des incohérences
Les institutions financières manipulent de grandes quantités de données sensibles. Grâce à des algorithmes avancés, la DO assure l'intégrité des flux de données utilisés dans les rapports financiers.
Cela permet de corriger immédiatement les erreurs qui pourraient affecter la conformité réglementaire et la confiance des parties prenantes.
Optimisation des coûts et des performances des pipelines
Dans le secteur B2B SaaS, la qualité des bases de données clients influence directement l'efficacité des campagnes marketing. L'observabilité améliore l'efficacité des flux en repérant les goulets d'étranglement.
Elle permet aussi de repérer les doublons, les erreurs de saisie ou informations obsolètes. De cette façon, elle améliore la performance des pipelines de données et l’efficacité des stratégies d’acquisition et de fidélisation.
Conclusion
La data observability est essentielle pour garantir des données fiables, repérer les erreurs en temps réel et optimiser les processus analytiques. En assurant une surveillance continue, elle améliore la prise de décision et réduit les risques opérationnels.
Étape essentielle d’une MDS, elle permet de sécuriser vos pipelines de données et d’assurer des analyses précises, indispensables à toute stratégie data-driven.
N’hésitez pas à nous contacter pour découvrir notre solution de Reverse ETL afin d'activer vos données en toute confiance !
FAQ
Quels sont les principaux piliers de l’observabilité des données ?
Les principes fondamentaux de la data observability incluent la fraîcheur, la distribution, le volume, le schéma, et le lineage.
La fraîcheur évalue l'actualité des données, tandis que la distribution examine les valeurs attendues pour identifier les incohérences.
Le volume mesure l'ampleur des données collectées, et le schéma en vérifie la constance de la structure. Le lineage, quant à lui, cartographie l'origine et le cheminement de la donnée.
Ensemble, ces cinq concepts jouent un rôle déterminant dans le suivi et l'évaluation de la qualité, de la disponibilité, et de la cohérence des données à travers tout le système.
Comment savoir si mon entreprise a besoin d’une solution de data observability ?
La DO est une composante parfois oubliée d’une Modern Data Stack.
Voici quelques questions à vous poser pour savoir si vous avez besoin d'une solution :
Traitez-vous de grands volumes de données au quotidien ?
Rencontrez-vous des erreurs récurrentes dans vos rapports ou analyses ?
Vos collaborateurs passent-ils trop de temps à identifier et corriger des anomalies ?
Avez-vous du mal à préserver l’intégrité et la précision des données utilisées ?
Souhaitez-vous automatiser la surveillance de vos pipelines de données ?
Défis et limites de la data observability
Complexité de déploiement : déployer une solution de DO demande une bonne compréhension des flux de données et des systèmes internes. L’intégration des outils et le suivi en temps réel des pipelines peuvent s’avérer techniques et chronophages.
Culture data-driven : l’observabilité nécessite une culture axée sur la donnée. Il est essentiel de former les équipes, de favoriser la collaboration entre départements et d’exploiter les données collectées pour la prise de décision.
Coût et maintenance des outils : les solutions avancées de data observability impliquent des coûts d’abonnement, de support et de mise à jour, auxquels s’ajoutent les frais liés au stockage et à la gestion des données, en particulier dans des environnements cloud.
Cependant, les bénéfices à long terme en matière de performance et de prise de décision compensent souvent ces défis.
*Source : Gartner