













Tracking server-side : définition, avantages et implémentation
6min • Édité le 9 avr. 2025


Alexandra Augusti
Chief of Staff
Pour pouvoir avoir des analyses marketing complètes ou optimiser ses performances publicitaires, il est nécessaire de suivre le comportement de ses clients sur son site internet. Historiquement, le tracking client-side a longtemps été la solution de référence, étant simple à implémenter. Pourtant, et encore plus depuis la fin des cookies tiers, les avantages du tracking server-side sont évidents : entre autres, une meilleure gouvernance, fiabilité, stabilité et un enrichissement des données collectées possibles.
Bien qu’existant et encouragé depuis 2020 avec l’introduction de GTM server-side, le tracking coté serveur a encore du mal à s’imposer au sein des entreprises. Cet article vise donc à expliquer les différences entre le tracking client-side et le tracking server-side et à mettre en avant les avantages de ce dernier.
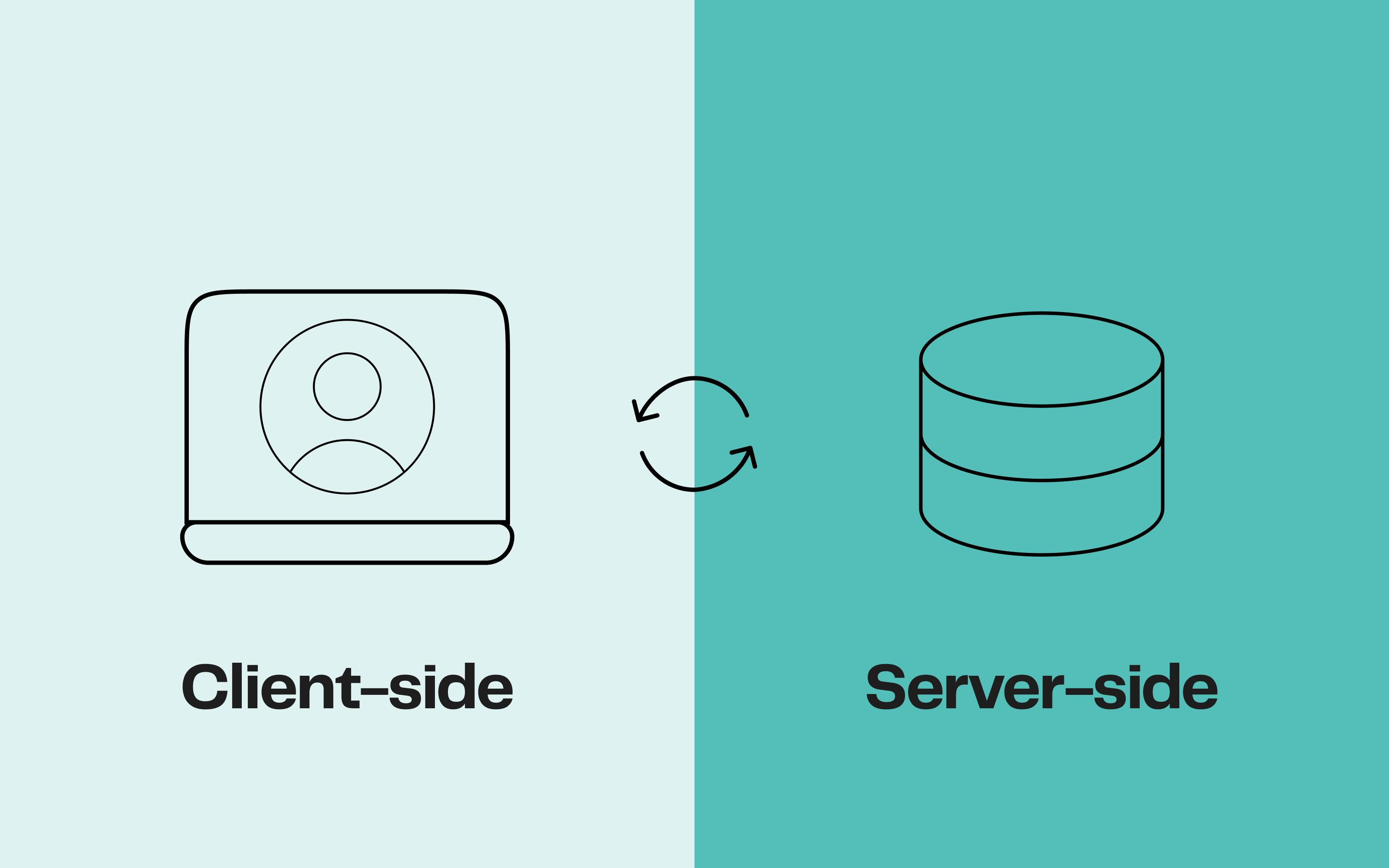
Tracking server-side vs. tracking client-side : de quoi parle-t-on ?
Le suivi, aussi connu sous le nom de tracking, constitue le processus par lequel on collecte et analyse les données de comportement des utilisateurs sur le web ou sur les applications mobiles. Cela offre la possibilité d’avoir des rapports exhaustifs sur les activités des internautes et d’alimenter les algorithmes des plateformes publicitaires avec des données comportementales.
Il existe deux méthodes de suivi : le tracking côté serveur (server-side) et le tracking côté client (client-side).
Le tracking client-side
Le tracking côté client se réalise sur le navigateur ou sur l'appareil de l'utilisateur, via l'utilisation de scripts JavaScript ou de pixels de suivi. La collecte de données se fait grâce à des balises, dont le déclenchement est géré par un gestionnaire de tags (TMS, Tag Management System), en transmettant les informations directement depuis le navigateur jusqu’à la destination marketing.
Historiquement, le tracking côté client a été largement privilégié pour la collecte de données web, en raison de sa simplicité de mise en place et de la capacité à fournir des résultats en temps réel. Toutefois, cette méthode comporte plusieurs limites et inconvénients, en particulier sur les plans de la fiabilité, de la performance, de la sécurité et du respect de la vie privée.
Les données collectées en client-side sont en effet de moins en moins complètes, notamment à cause des erreurs de chargement côté client, de l’utilisation des adblockers et des limitations technologiques au niveau des navigateurs (fin des cookies tiers, ITP d’Apple, Enhanced Tracking Protection de Firefox, etc.). Le tracking client-side est également affecté par le chargement potentiel de scripts tiers corrompus ou malveillants.
Le tracking server-side
À l’inverse, le tracking côté serveur est une approche de collecte de données effectuée directement sur le serveur. Les données sont recueillies et envoyées à un serveur, qui les redirige ensuite vers une API ou un point de terminaison spécifique, tel que Google Analytics, Facebook, ou d'autres outils d'activation de la donnée (data activation: CRM, marketing, analytics, etc.).
Dans ce cadre, le serveur joue le rôle d'intermédiaire entre l'utilisateur et la destination des données, ayant la capacité d'effectuer des traitements supplémentaires sur les données avant leur transmission.
💡 Le tracking server-side peut aussi être implémenté grâce à son TMS, à l’image de Google Tag Manager (GTM) qui a lancé sa version GTM server-side dès 2020.


Tracking client-side vs. server-side
Les avantages du tracking server-side
Le tracking côté serveur présente un éventail d'avantages comparé au tracking traditionnel côté client. Ces avantages englobent différents facteurs, allant de l'amélioration de la performance web à l'adéquation avec la RGPD, sans oublier l'exactitude du suivi publicitaire et le développement du volume de données recueillies.
👇 Pour toutes les raisons décrites ci-dessous, nous vous recommandons vivement de déployer un tracking server-side pour suivre les activités sur votre site internet :
Limitation des pertes de données liées au tracking client-side
Le tracking côté serveur est avantageux pour contrer la perte de données provoquée par les bloqueurs de publicités, les navigateurs dotés de fonctions anti-tracking ou encore les latences de connexion côté client. Ces éléments peuvent en effet altérer les requêtes du tracking provenant du navigateur, sous-estimant ainsi le trafic et les conversions réelles.
En migrant le tracking sur le serveur, qui fait office de proxy entre l’utilisateur et la destination finale, les risques de détection ou de modification par les bloqueurs de publicités ou les navigateurs sont réduits.


Illustration de la baisse des informations disponibles
Gouvernance et sécurité des données
Le tracking server-side vous permet de déterminer précisément quelles données sont collectées, mais surtout quand et comment elles sont transmises à des partenaires externes. Cela vous permet de choisir les informations essentielles pour vos analyses et initiatives marketing, tout en veillant à la confidentialité de certaines données.
De plus, vous avez la capacité de filtrer les données personnelles ou sensibles pour garantir la protection de la vie privée et la conformité RGPD. En collectant le consentement des utilisateurs avant le transfert des données et en respectant leurs préférences en matière de cookies, le tracking server-side permet un contrôle complet des données.
Enfin, en choisissant quand les données sont envoyées aux plateformes tierces, le tracking server-side permet de maintenir les données first-party dans le temps et donc de reconnaître un même utilisateur sur une période plus longue.
Enrichissement des données transmises
Grâce au tracking côté serveur, vous pouvez augmenter la qualité des données envoyées aux plateformes externes en y ajoutant des attributs first-party. Par exemple, il est possible d'associer le comportement des utilisateurs sur votre site aux données personnelles ou démographiques pour avoir une vision plus complète de vos clients.
Cette pratique permet d’enrichir les hits envoyés aux plateformes ads et donc d’améliorer le taux de matching entre les utilisateurs de votre site web et les utilisateurs de la plateforme publicitaire concernée. Un meilleur taux de matching implique directement des audiences plus complètes et donc de meilleure qualité, augmentant les performances marketing.
Stabilité dans le traitement des données
Le tracking server-side garantit une stabilité constante dans le traitement de vos données, éliminant ainsi les problèmes de connexion durant les périodes de forte affluence comme les soldes ou le Black Friday. Cette méthode diminue la dépendance vis-à-vis des performances du navigateur ou du dispositif client, qui peuvent varier selon de nombreux facteurs.
Avec le tracking server-side, puisque les données sont traitées sur des serveurs avec une infrastructures permettant de traiter des requêtes bien plus puissantes, la gestion des volumes importants de données se fait plus aisément.
Amélioration de la performance web
🌟 Le tracking server-side n’a pas que des avantages pour les ads et l’analytics !
Le suivi côté serveur contribue également à l'optimisation des performances de votre site web, notamment en accélérant le chargement des pages. En réduisant la quantité de scripts et de balises exécutés côté client, le tracking côté serveur allège le travail du navigateur et favorise un affichage plus rapide du contenu. Cela améliore l'expérience utilisateur et a un impact positif sur le SEO, puisque les moteurs de recherche privilégient les sites rapides et réactifs.
Quand devez-vous mettre en place un tracking server-side ?
Généralement, le suivi côté serveur est préconisé pour deux raisons principales : améliorer l'analyse des données et affiner les stratégies publicitaires.
💡 Si vous n’êtes pas encore mature sur ces sujets-là, nous vous conseillons d’abord de consolider vos bases avant de mettre en place ce type de tracking. En effet, les options de tracking server-side ne sont pas triviales et peuvent nécessiter une maîtrise technique des sujets data marketing plutôt avancée.
La collecte côté serveur permet en effet d’obtenir des informations plus détaillées qui facilitent des analyses poussées. En limitant la perte de données par rapport au tracking client-side et en maintenant les données first-party dans le temps, les tableaux de bord de rétention et d'attribution sont bien plus fidèles à la réalité.
Le tracking côté serveur est aussi un atout précieux pour affiner votre stratégie publicitaire, grâce à l'envoi de données plus complètes et qualitatives à des plateformes externes, telles que Google Ads, Meta Ads, ou autres réseaux de publicité. Grâce au tracking server-side, vous pouvez améliorer le taux de correspondance (taux de matching) entre les diverses plateformes. Cela vous aide à mieux cibler et segmenter vos audiences, à générer des lookalike plus pertinents (car basés sur des données plus complètes), à optimiser vos campagnes en fonction des objectifs de conversion, et à retargeter de manière plus exhaustive vos utilisateurs.
D’une manière générale, la mise en place d’un tracking server-side permet de diminuer considérablement son ROAS.
Le tracking server-side est-il suffisant ?
Le tracking server-side permet uniquement de suivre les conversions online
Si le tracking côté serveur apparaît comme une réponse adéquate pour recueillir et transférer les données de conversion online, il est toujours possible d’aller plus loin - notamment pour les ads et l’analytics pour des entreprises qui ne sont pas des DNVB.
Dans de nombreux cas, vous ne suivez pas seulement les interactions sur votre site web. Le suivi des événements est souvent réparti entre plusieurs solutions point-à-point utilisées pour alimenter votre activité :
Événements de leads dans le CRM
Événements d'utilisation du produit dans vos backend produit
Événements d'engagement dans votre outil d’analytics
Événements d'achat en magasin ou appels téléphoniques dans vos bases de données offline
Tous ces événements sont nécessaires pour reconstruire de manière conforme le parcours de vos clients. La prise en compte de ces événements est cruciale car ils offrent une vue à 360° de vos clients, accentuant ainsi votre capacité à évaluer l'impact réel de vos campagnes publicitaires sur les ventes effectives (analytics) et permettant d’optimiser les algorithmes des plateformes publicitaires (ads).


Customer 360, qui centralise toutes les données sur un client / prospect
La réalité est que vos clients peuvent être influencés par vos annonces en ligne mais concrétiser leur achat de manière hors ligne, et vice versa. Ignorer ces conversions hors ligne pourrait conduire à une mauvaise évaluation de l'efficacité de vos campagnes, impactant ainsi la gestion de votre budget et de votre stratégie marketing.
Comment transmettre les données offline ?
Pour éviter la déperdition des événements et l’envoi en double de toutes les touches client, il est recommandé de collecter puis centraliser tous les événements (online comme offline) dans un data warehouse cloud.
⚠️ Dans tous les cas, nous recommandons de ne pas utiliser son CRM comme Single Source of Truth, les data warehouse offrant de meilleures fonctionnalités en termes de centralisation et gestion des données collectées par les entreprises.
💡 Si vous avez besoin d’aide sur la mise en place de votre infrastructure data, n’hésitez pas à nous en faire part ! Nous serions heureux de prendre un café avec vous pour discuter de vos enjeux.
Ensuite, l’utilisation de solutions comme les API de Conversions est vivement recommandée.
Ces solutions facilitent la communication directe entre votre serveur et les plateformes publicitaires ads. L’avantage par rapport au tracking server-side configuré sur Google Tag Manager (ou autre gestionnaire de tags) est que les API de Conversions sont spécialement conçues pour intégrer les données de conversion hors ligne en les associant aux interactions online. Ici encore, il est possible d’ajouter des données first-party à ces conversions pour les enrichir au maximum, et donc améliorer le taux de matching côté plateformes ads.
Cette technique vous permet de rattacher chaque conversion hors ligne à la campagne publicitaire correspondante, offrant ainsi des analyses plus détaillées et fiables de votre ROI.
La plupart des plateformes publicitaires (Google, Meta, Snapchat & Tiktok) mettent à disposition des API de Conversions.
💡 Si vous souhaitez une solution qui vous permet de faire les deux à la fois, passez par des outils par DinMo ! Notre solution offre la possibilité d’envoyer des conversions à la fois online et offline directement depuis votre data warehouse cloud en quelques clics. Vous pouvez également modifier les valeurs de vos conversions a posteriori.


Activation des données en quelques clics
Conclusion
Le tracking server-side se présente comme une solution robuste de collecte et de gestion des données web et mobiles, opérant depuis le serveur, en dehors du navigateur ou de l'appareil de l'utilisateur. Cette méthode avance des avantages notables face au tracking client-side, en offrant plus de fiabilité, une meilleure performance, une sécurité renforcée et une approche plus respectueuse de la vie privée.
Recommandé pour devenir data-driven et maximiser l'efficacité publicitaire, le tracking-server permet une transmission de données plus riche et de meilleure qualité aux plateformes tierces. Ajoutée à cela, l'utilisation des APIs de conversions pour intégrer efficacement les données offline aux mesures en ligne peut offrir une appréciation d'autant plus précise et réaliste du parcours client, ainsi qu'un calcul optimisé du retour sur investissement.
En bref, ces solutions techniques sont essentielles pour une efficacité marketing accrue et nous pouvons que vivement recommander leur mise en place.
Si vous souhaitez en savoir plus sur les solutions de tracking server-side ou les APIs de conversions et leur mise en place, n’hésitez pas à nous contacter. Nous serions heureux de partager nos meilleures pratiques sur les sujets de data marketing !












